Roast Reference Manual |
0. Table of Contents
1. Introduction
Roast is a framework designed to support automated testing of Java APIs. Roast scripts are typically highly automated, with programmatic input generation and output checking. While Roast has been applied primarily to drivers for container classes (object-oriented abstract data types), Roast is applicable to many APIs where the principle interaction is through method calls rather than files, keyboard, or mouse.Roast is implemented as a Perl preprocessor plus a variety of Java abstract and concrete classes. Roast templates provide macro-like support for recurring test patterns. The Roast framework is based on a set of four unit operations: generate, filter, execute and check. Each unit operation is implemented as an abstract class. The unit operations communicate via test tuples, each of which is an abstraction of a concrete test case. Roast provides methods for tuple generation, based on generalizations of cartesian product.
Because test drivers frequently produce large log files, Roast provides support for log message generation, filtering and viewing.
Roast is invoked from the Unix command line. Support is provided for a variety of standard roast arguments and for custom arguments used in a particular.
2. Test Templates
Roast supports two test templates, each providing macro-like support for commonly occurring test patterns. Templates are embedded in Java test drivers and are identified by keywords preceded by the "#" character. The templates are expanded by a Perl preprocessor, resulting in compilable Java code.This section uses the running example shown in Templates.script. Some of the test cases are intentionally flawed, to illustrate how Roast reports failures. The file Templates.out contains the complete output of the driver.
The value-check template
The value-check template has syntax#valueCheck expVal # actVal [# valueType] #end
where expVal and actVal are Java expressions of comparable types.
From this case, Roast generates code to compare expVal and actVal, while monitoring exception behavior. The generated code prints an error message if expVal and actVal are not equal or if an exception is thrown during the comparison.
In Templates.script are 8 value-checking templates. At the start, string s is created with initial value "abc". Case V1 checks that s has length 3. Case V2 checks, incorrectly, that s has length 0; this case will generate an error message. Case V1 checks that s has value "abc".
If expVal and actVal are of type
Object, String, boolean, char byte, short, int, long, float, doublethen they are compared in the obvious way, using code provided by Roast. For other types, the tester can provide custom comparison routines. This is done by extending the ValueType class and implementing the compareValue and printValue methods. In Templates.script, the class CIString implements case-insensitive comparison of strings. Case V4 compares s to "abc", using the builtin comparison whereas V5 uses the CIString code. Case V6 fails (intentionally) because s contains "abc" not "aBc". Case V7 uses the CIString comparison and passes. Finally, case V8 shows what happens when an exception is thrown during the evaluation of expVal or actVal.
Note: when a value check template fails, expVal and actVal are evaluated twice: once for comparison and again while generating the error message. This can cause problems if they have side-effects.
The exception-monitor template
The exception-monitor template has syntax#excMonitor action # expExc [# exceptionType] #end
where action is a Java code fragment, expExc is an object whose type is a subclass of Throwable, and exceptionType is a subclass of ExceptionType.
From this template, Roast generates code to execute action while monitoring exception behavior. The generated code prints an error message if expExc is not thrown or if another exception is thrown. If expExc is omitted, then an error message is generated if any exception is thrown.
In Templates.script are 6 exception-monitoring templates. Test case E1 requests a character at a legal position in s; no exception is expected. Test case E2 intentionally requests a character at an illegal position. Since an exception will be thrown and no expected exception field was specified, an error message will be generated. In cases E3 and E4, the same method calls are made, but an expected exception is specified.
In an exception-monitoring template, if the exceptionType field is omitted, then comparision is done based on the class of the exception objects. Two exception objects are considered equal if they have exactly the same type. For other types, the tester can provide custom comparison routines. This is done by extending the ExceptionType class and implementing the compareException and printException methods. In Templates.script, the class MyExcCompare implements custom comparison of exceptions of type E. In case E5, two E objects are found to be equal, using the default comparison based only on object type. In case E6, the two E objects are found to be unequal, because the custom comparison checks the value of the field x in class E.
3. Unit Operations
Tuple testing
Tuple testing uses tuples to specify test cases. The tuple semantics determine how the tuple maps to a corresponding test case. The tuple syntax determines the number of elements in the tuple and their data types. Each element of a tuple <d0,...,dn-1> is taken from a domain: a set of elements, often ordered, of the same data type. A domain may be a set of integers, a set of object references, or some other type. For an n-tuple, the tuple space is defined by the Cartesian product of the n domains.Similar to table-driven programming, each tuple can be viewed as a table row and each tuple element can be viewed as a table column. In tuple testing, each tuple (row) is processed one at a time and is an independent, abstract representation of a test case. If the number of test tuples is large, then this approach yields a shorter and simpler test driver.
Tuple testing supports pipe-style test drivers. Using a simple tuple interface, streams of test tuples can be piped between different driver operations. This uncouples the operations and makes them easier to reuse in other drivers.
Roast unit operations
Roast partitions test drivers into four unit operations: generate, filter, execute, and check. Each operation has a precise interface and can be used repeatedly in different test drivers. Each unit operation is implemented as an abstract class. Tuples, representing test cases, extend the AbstractTuple class. The four unit operations, in order, are:- Generate: constructs the test tuple set containing all tuples used in the driver. The test tuple set may be the entire tuple space or, more often, a subset of it. The tester extends the GenerateUnitOp class and implements its two abstract methods.
- Filter: removes tuples from the test tuple set. Many of the generated tuples may be invalid or undesired and need to be filtered out. The tester extends the FilterUnitOp class and implements its abstract method.
- Execute: transforms a tuple into a test case and executes the test case. Since a tuple is an abstract representation of a test case, it cannot be directly executed. Tuple elements are first used to construct a test case, which is then executed on the CUT. Calls to CUT methods are usually invoked in #excMonitor test case templates. Typically, the tuple is updated to include results of the test case execution. The tester extends the ExecuteUnitOp class and implements its abstract method.
- Check: implements the oracle. To check the result of a test case, the tester extends the CheckUnitOp class and implements its abstract method.
Example
Suppose we need to test the append method of StringBuffer. The method takes a String and appends it to the StringBuffer. To test this method, we need a simple way to initialize strings of varying length, generate test cases, and check their result. Our Roast test driver, AppendUnitOp.script, uses fill strings with "abcde" repeated as necessary and illustrates the interaction between the four unit operations. Figure 1 gives an overview of this interaction and shows the 3-tuples <n0, n1, s> passed between unit operations:- n0: the length of the first StringBuffer
- n1: the length of the second StringBuffer
- s: the resulting StringBuffer
The AbstractTuple class is extended to add these three elements.
Figure 1: Unit Operations in AppendUnitOp
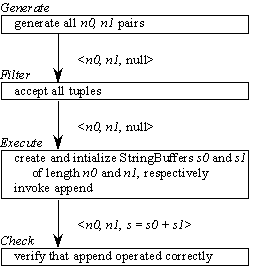
The four unit operations used in AppendUnitOp are as follows:
- Generate: constructs the tuple space of 3-tuples <n0, n1, null>. The range for the n0 and n1 domains is the same: [0..MAXLENGTH], where MAXLENGTH is a constant. The tuple space contains one tuple for each pair in the Cartesian product of the two domains. When the Generate object is instantiated, a Vector containing all tuples is created. Each call to nextTuple() removes and returns the last tuple in the Vector; hasMoreTuples() returns true until the Vector is empty.
- Filter: no tuples are invalid so isValidTuple(T) returns true.
- Execute: creates two StringBuffers, s and s1 of length n0 and n1, respectively. The StringBuffers are filled with the fill pattern, "abcde". s1 is appended to s.
- Check: verifies that s and s1 were appended correctly. In #valueCheck test case templates, the characters of s are compared to the expected fill pattern.
The driver class contains a straightforward main method. The main method initializes the fill pattern, passes the command-line arguments to the framework then starts the framework with a call to its static startUnitOps method. This method takes an instance of each of the unit operations and does not return until all the tuples in the tuple set have been generated, filtered, executed, and checked.
4. Tuple Generation
Roast provides support for tuple generation based on variations of the cartesian product operation. In each case, the tester provides a Vector of Domain (defined below) and Roast returns an iterator. If the Vector contains N Domains, then each call to the iterator returns an n-tuple represented as a Vector with N elements. Typically, each n-tuple is then converted to a Tuple for use in the generate unit operation.The driver Generate.java demonstrates the tuple generation operations; The driver output is Generate.out
Domains
In Roast, a domain is a vector-like object.
More specifically, a
Domain
is a Java interface requiring methods size, elementAt, and toString.
The tester can implement Domain in a variety of ways.
Roast provides
IntervalDomain
to generate a domain consisting of a contiguous sequence of integers, and
VectorDomain
to encapsulate a Vector as a Domain.
Cartesian product
The CPIterator class
provides tuple generation based directly on cartesian product.
The CPIterator constructor takes a Vector of Domain
and provides a Java Iterator.
The driver Generate.java begins by creating two domains, alphaDomain and intervalDomain, and loading them into domainVector. Then domainVector is passed to the CPIterator constructor and each element in the iterator is retrieved.
The driver AppendCP.java shows the use of CPIterator in the Generate unit operation.
k-Boundary The BdyIterator class provides tuple generation based directly on a variation of cartesian product. For a single Domain of length N, the 1-bdy is the pair consisting of the elements in positions 0 and N-1, the 2-bdy is the elements in positions 1 and N-2, and so on. For 2 or more domains, the 1-bdy is the cartesian product of the 1-bdys of the individual domains. As with CPIterator, the BdyIterator constructor takes a Vector of Domain and provides a Java Iterator.
The driver Generate.java passes the domainVector containing alphaDomain and intervalDomain to the BdyIterator constructor with k set to 1 and then each element in the iterator is retrieved. Next the same procedure is followed with k set to 2.
The driver AppendBdy.java shows the use of BdyIterator in the Generate unit operation.
Dependent domains While CPIterator and KBdyIterator are good for generating tuples from independent domains, they are less effective when one domain is defined in terms of another. Consider testing the elementAt method of the Vector class. We might generate one Vector for each length n in [1..N] and then, for each n, invoke elementAt(0) and elementAt(n-1). Thus, we need to generate two length/index pairs for each n value, except for n = 1 which has only the pair (1,0). It is not possible to generate these pairs, and no others, with CPIterator or KBdyIterator.
With a dependent domain, we take a vector of n-tuples and a single domain, and generate (n+1)-tuples, by extending each n-tuple with a different element from the domain. We call the n-tuple the base tuple and the domain a dependent domain, because the elements used to extend a base tuple are recalculated for each base tuple.
To facilitate the generation of dependent domains, Roast provides the Factory interface and the ExtendIterator class. The Factory interface provides a single method, {\tt create}, which takes a vector and returns an iterator. The ExtendIterator constructor takes two arguments: an iterator i, which generates the base tuples, and a factory f, which for each tuple t generated by i, creates an iterator i' that generates the elements from the dependent domain that extend t.
The driver Generate.java shows how to generate length/index pairs using Factory and ExtendIterator. The length values are generated using IntervalDomain and the DomainIterator class, an adapter that converts a Domain to an Iterator. The IndexIterator class generates an iterator containing a pair of index values for the length value passed to its constructor.
The driver SubstrCP.script shows how to test the substr method of StringBuffer using CPIterator. The driver is inefficient in that many of the generated tuples are discarded by Filter, because the start/end values are out of range. The driver SubstrDD.script overcomes these problems by using Factory and ExtendIterator to generate only the legal values.
5. Log Messages
Roast provides facilities for logging and viewing messages generated during test case execution. Each message has an associated type and level. A graphical user interface has been created to view Roast messages in a hierarchical manner.Message levels
During debugging, when failures are most likely to occur, it is often desirable to generate many detailed log messages. However, generating all these log messages during normal regression testing would obscure the important messages by producing a lot of unnecessary output. Therefore, all Roast messages have an associated level. The message is printed only if its level is less than the current Roast message level, which can be set for each test run from the command line. Thus, during regression testing, drivers are executed with the lowest possible message level to generate and display only the failure messages and summary statistics. During debugging, the message level is increased to provide comprehensive debugging traces. This approach achieves flexibility without recompiling the test driver.Message types
There are two types of Roast log messages: failure messages (logged by Roast when a test case fails) and utility messages (logged by the tester).
Message control and viewing
By default, Roast log messages are output to the command line. Using Roast command line parameters, log messages can be directed to a log file, either as plain text or serialized log message objects. The format for log message output to the command line and to plain text log files is identical. Figure 2 shows the messages output from LogMessageDemo, run with a command line message level of 4. Each message is indented with n tabs, where n is the message's level. A message level of zero means the message is left justified against the left margin. The two failure messages are logged by the failed #valueCheck and #excMonitor test case templates. Similarly, Figure 3 shows messages output from LogMessageDemo, run with a command line message level of 0.
Level 0 message Level 1 message Level 2 message Value error at line number: 13. Actual value: true Expected value: false Level 3 message Level 1 message Level 2 message Level 3 message Level 4 message Level 3 message Exception error at line number: 20. Actual exception: <none> Expected exception: java.lang.Exception Level 4 message Level 4 messageFigure 2: Levels 0 through 4 LogMessageDemo messages output to the command line
Level 0 message Value error at line number: 13. Actual value: true Expected value: false Exception error at line number: 20. Actual exception: <none> Expected exception: java.lang.ExceptionFigure 3: Level 0 LogMessageDemo messages output to the command line
The Roast Log Message Viewer, a graphical user interface (GUI) application, allows variable amounts of message detail to be viewed. The application loads and displays serialized log messages. As shown in Figure 4, this application displays messages using a tree. In this horizontal tree layout, a message is inserted in the tree at the height indicated by its message level. Higher-level messages are nested to the right of lower level messages. Failure messages, however, appear at the same level as the previously logged message. The application allows us to search for failure messages and selectively expand and collapse log messages.
Figure 4: Roast Log Message Viewer application
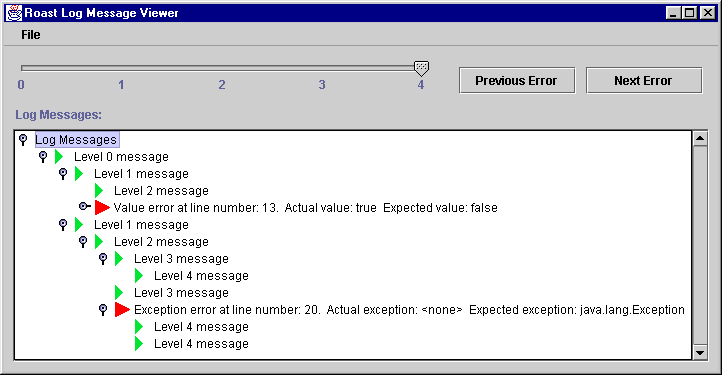
Figure 4 shows all messages expanded. A failure message is indicated by a red triangle to the left of the message text and a utility message is indicated by a smaller green triangle. The slider control along the top of the application allows us to expand all messages with levels less than or equal to the selected slider value; the rest are collapsed. Starting from the currently selected message, the Previous Error and Next Error buttons select the previous or next failure message, expanding messages as necessary. File menu items allow serialized log files to be loaded and the application to be shutdown.
6. Command Line Invocation
Roast system overview
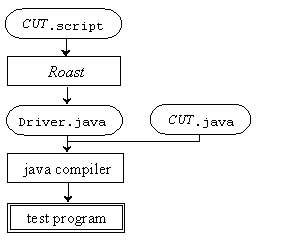
In the Roast flowchart shown in Figure 5, ovals indicate human-readable files and boxes indicate executable programs. The tester writes a test script for the code under test (CUT) in the file CUT.script. The test script contains Roast test case templates embedded in Java code. Roast processes this script and generates a Java program in Driver.java. The driver and the CUT are then compiled. When the resulting test program is executed, the test cases in the test script are run against the implementation and any errors are logged.
Figure 5: Roast system flowchart
Command-line arguments
The Roast parseArgs method parses the command-line arguments. The CommandLineDemo.java demonstrates how to specify your own, custom command-line arguments to supplement those specified by Roast. Briefly, you specify your custom flags with FlagSpec objects and then pass them in an array to the parseArgs method.
Commands
To convert CUT.script into Driver.java, execute the command:
roast < CUT.script > Driver.java
To compile the resulting driver, execute the command:
javac Driver.java
To run the driver, execute the command:
java Driver [command line options]
To run the Roast Log Message Viewer, execute the command:
java roast.viewer.LogViewer [serialized message file]