Many of the current computer audition systems that have been proposed for music information retrieval purposes model a piece of music as a single entity and represent it by calculating descriptive statistics over the whole length of the song. Although this assumption is valid for a large percentage of commercial pop music it does not hold for other musical genres such as Classical and Jazz music where each piece contains a variety of sections with very different characteristics.
The term sound "texture" can be used to describe the characteristics that identify a particular section in a piece. Some examples of sound "textures" are the saxophone solo in a jazz recording, the string section in an orchestral piece, the refrain of a piece etc. As is the case with visual textures (such as grass or bricks), sound "textures" can not be precisely defined and can only be characterized by fuzzy properties that are statistical in nature.
Segmentation refers to the process of detecting these changes of sound "texture". Because of the large and possibly infinite number of sound "textures" of interest in music the approach of first classifying "textures" and then combining the results for segmentation that has been used for speech signals is not applicable.
We proposed a multifeature segmentation methodology for audio signals that doesn't rely on prior sound "texture" classification in 1999. The basic idea behind the algorithm is to look for abrupt changes in the trajectory of feature vectors over time and use the location of those changes as segment boundaries. Another important feature of the algorithm is that unlike classification-based algorithms it takes into account amplitude changes as a source of information.
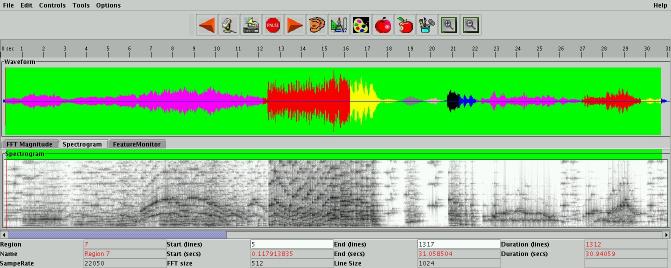
User experiments confirmed that there is significant agreement between humans when segmenting audio and that their performance can be approximated by automatic algorithms. The figure above shows the automatic segmentation of a piano Concerto by Mozart. It can be seen that in some cases the segment boundaries are visible to the human eye as changes in the spectrogram. More details can be found:
Feature Extraction from MP3 compressed data
George Tzanetakis and Perry Cook
The majority of existing audio and music data available on the web are compressed using the MPEG (Motion Picture Experts Grou) audio compression standard (the well known .mp3 files). MPEG audio compression is a perceptually-motivated lossy compression scheme where the properties of the human auditory system (HAS) in order to achieve compression up to about a tenth of the original audio file size. The main idea behind MPEG audio compression and other similar perceptually-motivated audio coders is that the signal is separated into frequency bands and each frequency band is then subsequently quantized. This quantization results into artifact that can be made perceptually inaudible by taking advantage of the "hardware" limitations of the human ear. In order to represent musical signals for subsequent classification, segmentation, and retrieval typically features that describe the audio content are automatically calculated. The main idea behind this project, is to calculate these feature directly on the compressed audio data without having to perform a subsequent analysis after decompression. In a essence, what is happening is that the analysis using during the encoding stage when the file is compressed is used as the analysis front-end for feature extraction. This idea was independently proposed by Tzanetakis and Cook, ICASSP99 and David Pye, ICASSP99. More details can be found:
Musical Genres are labels created and used by humans to categorize music. Although their boundaries are fuzzy, members of a particular genre typically share similar characteristics. Currently, genre classification on the web is done manually. Automatic genre classification has the potential to automate this process. Perhaps, even more important, genre classification is an excellent way to test different feature sets that attempt to rerpresent musical content and this the main reason I am interested in this problem. Most of the previous work in audio and music classification that I am aware of used various types of features that essentially represent the timbral "texture" of the sound. These feature originate and are also applicable to other types of audio such as speech and isolated musical instrument tones. However, music has distinct characteristics that separate from other audio signals such as pitch and rhythm content. In order to represent those aspects that are unique to music, I proposed two feature sets to represent rhythm (based on Beat Histograms computed using the Discrete Wavelet Transform) and pitch content (based on Pitch Histograms computed using a computational simplification of a perceptual multiple pitch analysis algorithm). It was shown that these features provide additional and valuable information for the task of automatic musical genre classification. Using the full feature set (timbral + rhythm + pitch) genre classification with accuracy 60% can be achieved using 10 classees (classical, country, disco, hiphop, jazz, rock, blues, reggae, pop, metal). An indirect comparison can be made with experiments with humans where on a different dataset containing also 10 genres, humans performed genre classification with accuracy around 70%. More information can be found at:

The image above is a static snapshot of the GenreGram a real-time dynamic 3D graphical display that displays classification results. Live radio signals are fed into the computer where feature extraction and genre classification are performed in real time. Each cylinder corresponds to a particular genre and the height of the cylinder corresponds to the classification confidence for that particular genre. (TO DO ADD VIDEO CLIP)
Beat Analysis and Beat Histograms using the Discrete Wavelet Transform
One of the important characteristics of music that separates from other times of audio signals is the precense of Rhythm which can loosely be defined as hierarchically repeating structures in time. Probably the most important aspect of rhythm is the beat which can be loosely defined as the rate of human foot tapping while listening to a piece of music and in many cases corresponds to the most dominant periodicity at the right frequency range corresponding to rhythm perception. Most of existing algorithms proposed in the literature deal with the problem of beat tracking where a running estimate of the main beat is computed. In contrast Beat Histograms are a global (over the whole piece) representation of rhythm. Each histogram bin corresponds to a particular tempo in Beats-per-minute (BPM) and the corresponding peak shows how frequent and strong that particular periodicity was over the entire song. The key insights that led to the development of Beat Histograms are: 1) a global representation is more robust for the purposes of similarity retrieval and classification 2) the failure or success of a beat detector is a source of information that is as if not more important that the beat tempo itself 3) That more information than just the main beat might be useful for similarity retrieval and genre classification. The following figures and corresponding sound files hows some examples of Beat Histograms and by visual inspection one can see that it is probable that features derived from the BH can be used for genre identification. This hyphothesis has been confirmed with experiments in automatic musical genre classification using features derived from Beat Histograms. Things to notice: the location of the main peaks correspond to the dominant tempos of the music and their height to how strongly self-similar the signal is for those tempos. A gradual change from few strong dominant peaks to many spread ones can be observed (HIPHOP->ROCK->JAZZ->CLASSICAL)
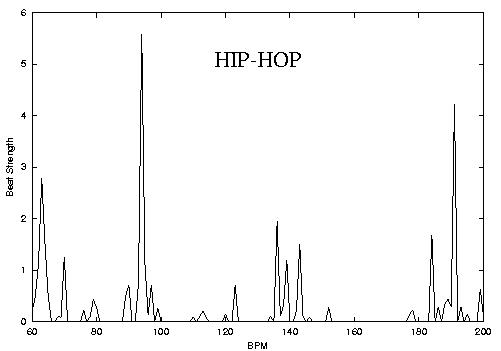
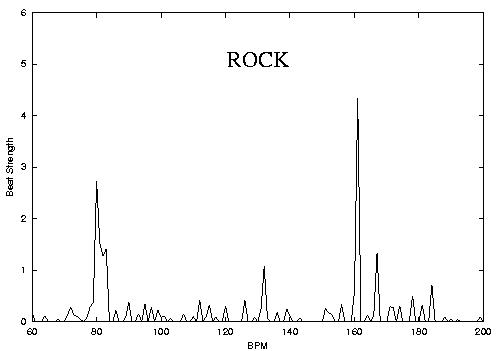
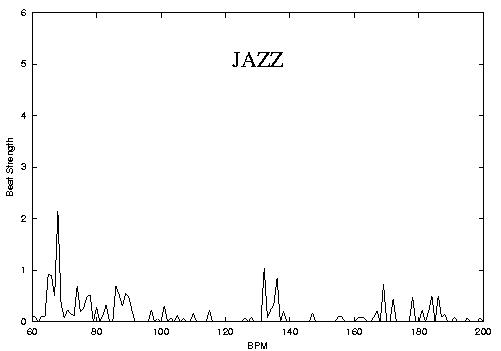
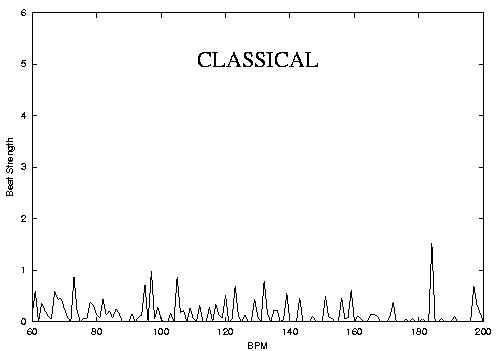
Classical song (30 seconds mp3)
The Discrete Wavelet Transform is a time-frequency analysis methods that has been proposed in order to overcome some of the disadvantages of the Short Time Fourier Transform. A method for the calculation of Beat Histograms based on the DWT as well as a set features derived from Beat Histograms for describing rhythmic content have been been proposed. More details can be found at:
Multiple Pitch Detection and Pitch Histograms
Most of the currently proposed feature sets for representing musical content of audio signals are based on statistics of spectral information that essentially try to capture the timbral "texture" of a musical piece. In addition to such information, most of recorded music is based sounds falling on a logarithmically spaced frequency grid that corresponds to the musical pitches. Although the complete extraction and separation of pitches from arbitrary polyphonic audio signals (called musical transcription) is still an unsolved problem there are several proposed algorithms for extracting multiple simultaneous pitches. These algorithms although not perfect can provide some statistical in nature information that can be used to augment other feature sets for classification, segmentation and similarity retrieval.
Because the error rate of such multiple pitch extraction algorithms is quite high it is necessary to come up with a global statistical description of the pitch content of a piece of music.
Content-based similirity retrieval
Under construction
Under construction
Under construction
Under construction
Human Perception and Computer Extraction of Beat Strength